

Following the announcement of our Spotlight paper at NeurIPS 2020, Prophesee releases the most comprehensive Event-Based dataset to date.
ADDRESSING THE PERFORMANCE CHALLENGE
Event cameras encode visual information with high temporal precision, low data-rate, and high-dynamic range. Thanks to these characteristics, event cameras are particularly suited for scenarios with high motion, challenging lighting conditions and requiring low latency. However, due to the novelty of the field, the performance of event-based systems on many vision tasks is still lower compared to conventional frame-based solutions.
The main reasons for this performance gap are: the lower spatial resolution of event sensors, compared to frame cameras; the lack of large-scale training datasets; the absence of well-established deep learning architectures for event-based processing.
OUR APPROACH
Our model, spotlighted at NeurIPS, outperforms by a large margin feed-forward event-based architectures.
Moreover, our method does not require any reconstruction of intensity images from events, showing that training directly from raw events is possible, more efficient, and more accurate than passing through an intermediate intensity image.
Experiments on the algorithmically generated dataset introduced in this work, for which events and gray level images are available, show performance on par with that of highly tuned and studied frame-based detectors.
You can see for yourself and explore the possibilities of this dataset with the machine learning module available in our Metavision Intelligence Suite.

Fig 1: Conv-rnn feature extractor for object detection unrolled in time
DATASET CONTENT
The dataset is split between train, test and val folders.
Files consist of 60 seconds recordings that were cut from longer recording sessions. Cuts from a single recording session are all in the same training split.
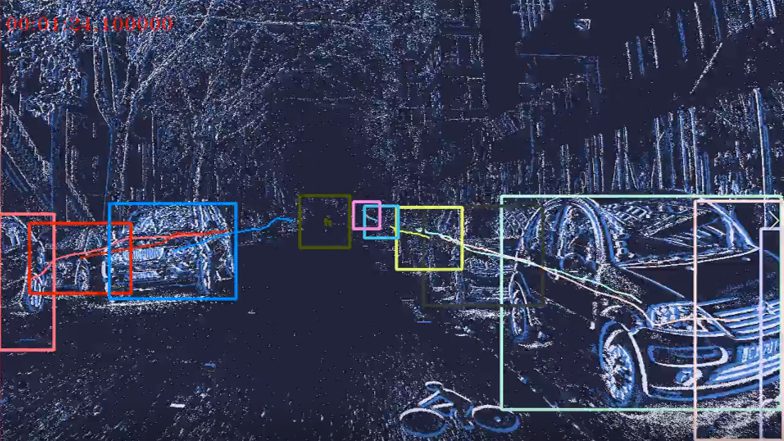
Each dat file is a binary file in which events are encoded using 4 bytes (unsigned int32) for the timestamps and 4 bytes (unsigned int32) for the data, encoding is little-endian ordering.
The data is composed of 14 bits for the x position, 14 bits for the y position and 1 bit for the polarity (encoded as -1/1).

Annotations use the numpy format and can simply be loaded form python using numpy boxes = np.load(path)
Boxes have the following fields
- x abscissa of the top left corner in pixels
- y ordinate of the top left corner in pixels
- w width of the boxes in pixel
- h height of the boxes in pixel
- ts timestamp of the box in the sequence in microseconds
- class_id 0 for pedestrians, 1 for two wheelers, 2 for cars, 3 for trucks, 4 for buses, 5 for traffic signs, 6 for traffic lights
Alongside the dataset, we also release sample code in Python to conveniently read the events and annotations: Github repository
For more information on how the dataset was created, please refer to the paper.
CITING PROPHESEE 1 MEGAPIXEL AUTOMOTIVE DETECTION DATASET
When using the data in an academic context, please cite the following paper:
Etienne Perot, Pierre de Tournemire, Davide Nitti, Jonathan Masci, Amos Sironi “Learning to Detect Objects with a 1 Megapixel Event Camera”. To appear in 34th Conference on Neural Information Processing Systems (NeurIPS 2020).

