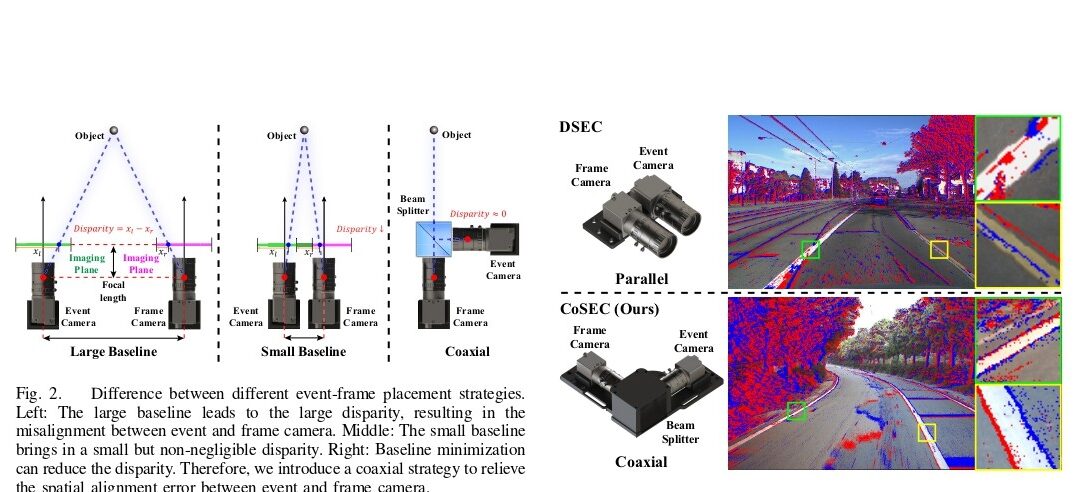
This paper introduces hybrid coaxial event-frame devices to build the multimodal system, and propose a coaxial stereo event camera (CoSEC) dataset for autonomous driving. As for the multimodal system, it first utilizes the microcontroller to achieve time synchronization, and then spatially calibrate different sensors, where they perform intra- and inter-calibration of stereo coaxial devices.
This paper presents Ev-Layout, a novel large-scale event-based multi-modal dataset designed for indoor layout estimation and tracking. Ev-Layout makes key contributions to the community by: Utilizing a hybrid data collection platform (with a head-mounted display and VR interface) that integrates both RGB and bio-inspired event cameras to capture indoor layouts in motion.
This paper presents dataset characteristics such as head pose, gaze direction, and pupil size. Furthermore, it introduces a hybrid frame-event based gaze estimation method specifically designed for the collected dataset. Moreover, it performs extensive evaluations of different benchmarking methods under various gaze-related factors.
Synthetic Lunar Terrain (SLT) is an open dataset collected from an analogue test site for lunar missions, featuring synthetic craters in a high-contrast lighting setup. It includes several side-by-side captures from event-based and conventional RGB cameras, supplemented with a high-resolution 3D laser scan for depth estimation.
Low-light environments pose significant challenges for image enhancement methods. To address these challenges, this work introduces the HUE dataset, a comprehensive collection of high-resolution event and frame sequences captured in diverse and challenging low-light conditions.